
Shaft Specifications
Shaft is a forwaring channel for LDAP data, with local caching in an LDAP server. It pulls complete subtrees from various sources and stores them locally under what may be another tree location. This is done almost live, by subscribing to updates. In addtion, Shaft can subscribe to a list of things to monitor, and dynamically create new tree locations that will henceforth be subscribed to. In case of clashes between sources, the Shaft resolves conflicts by queueing newer offerings after older ones.
This site reflects work in progress.
This specification details how Shaft can be used to pull information from a number of sources, and ensure that it is consistently available on the local network. When network conditions are normal, its updates can be instant; when the network fails, it continues to serve the the last-known-good state.
Realtime pulling: LDAP SyncRepl
The Shaft specification is based on LDAP SyncRepl (RFC 4533) which permits a mode refreshAndPersist that is perfect for receiving updates over a query outcome in real-time.
Design around Idempotence
Idempotence is a mathematical property; one could say it is the impotence of idem; repeating things is not going to add anything; repeating things is not going to add anything.
When an LDAP object is sent somewhere as an update, and it turns out to not have changed, then that change is ignored. The result will be that the flow of updates triggering updates stops. Similarly for deletions of objects that have already gone.
Idempotence is incorporated into the design of the Shaft where it helps to put an end to repeating pointless updates.
Design around Availability
A major concern for the Shaft is to have data available at all times, even in the presence of upstream network failures. This is established with a local cache, but the method of making changes to this cache are also important. Shaft is usually employed as a data cache on the local network, serving all Machines on it with a consistent data set. This local network is under more direct control and problems on it can usually be resolved quickly. This would not apply across arbitrary connections to other networks, and Shaft exists to separate those concerns. Remote downtime therefore does not lead to local downtime.
The SyncRepl mechanism publishes changes as series of updates and deletions, in that order. This order is used to avoid removal of objects before introducing their new versions or alternatives. For instance, when moving an object between locations, the new location is created first and only after that has succeeded will the old location be removed. This implements a usable form of referential integrity.
This line is normally easy to follow in an implementation, and it even gives a useful boundary for transactions on LDAP. But in some cases it may be a bit more difficult to avoid dropping state during a change. Consider the case where Shaft is configured to follow a few sources, and one of those drops while an alternative offering is already in place. Now, to avoid a glitch in the data, it is important to remove all old data (from the old source) and replace it with the data from the new source; this would take a bit of explicit work, namely to remove the old nodes only after the new ones have been added, and only those nodes that have not been replaced should be removed. Again, the total of this process is best treated as a transaction that makes the change as atomic as possible.
Design around Competing Subtree Origins
The basic design for Shaft is to pull in an entire (sub)tree from an upstream server, and replicate it locally under a possibly different subtree. This may be done for multiple upstream origins at the same time.
When so configured, Shaft will also pull a list of offered subtrees from the upstream server, and will try to map them to a local subtree automatically when new additions are made. This may lead to a situation where multiple upstream origins try to map to the same locally replicated subtree.
If this happens, then by default the oldest one wins. That is, once a subtree is occupied for an origin, other origins are queued behind it in the order in which they offer to provide for it, but they will not overtake what has been established. Only when the current origin falls away will the next one take over; and in doing so, an effort will be made to not even temporarily drop objects that occur in both the old and new version, with matching or different information.
The operator may override the selection and the order of the queue. This is done through manual interventions such as commandline operations and/or web-prepared submissions to a FastCGI component.
The queue and its configuration may be modelled as part of the LDAP directory or of a locally stored bit of information, such as in the filesystem.
Design around Optimistic Transactions
The SyncRepl specification separates runs of work, each usually comprising of a series of complete object rewrites and object deletions. It marks the end of such runs of work explicitly, but it does not assign any semantics to it. The only thing exchanged is a marker value that can be used as a last-known-good starting point when restarting SyncRepl in the future.
The SteamWorks read more meaning into the runs of work, namely as database transactions. LDAP always treates object updates as atomic, but there is no mechanism to make atomic updates that span multiple objects. Formally, any assumption of such semantics can at best be called optimistic, but if all components of SteamWorks implement the approach then a realistic opportunity arises to actually make it work.
This is why the runs of work presented by SyncRepl are downloaded completely before they are applied; and why they are run in a single transaction, inasfar as is possible given the LDAP backend.
By treating a run of work as a unit, it is also possible to detect the removal of an entire subscribed tree (for which the base node is removed after its child nodes) and a queued alternative can be subscribed to and installed without objects disappearing for the blink of an eye if they are present in the old and new situation.
Transactions (in the database sense) fulfil a number of properties:
-
Atomicity is the property of all-or-nothing; if an update fails it will be rolled back. In lieu of direct support for multiple-object transactions in LDAP this requires individual object updates to take the form of a diff, because that form can be applied in reverse. So, when a series of objects requires changes and a later object leads to errors then the changes on previous objects can be reversed. Alternatively, it is possible to use a Pre-Read Control to obtain the prior values of an object. In case of Shaft however, literal copies of subtrees are cloned, so there is no reason to expect any problems; the only place would be when switching the upstream origin of a tree.
-
Consistency includes things like referential integrity. This is not a property that can be guaranteed in LDAP, because the origin might not enforce that every object that refers to a DN actually has that DN available; and it couldn't, because that DN might not be local. This means that applications must always be mindful of dangling references, and program around it. In other words, consistency is not an issue in LDAP.
-
Isolation refers to the inability of other processes to see the intermediate state of a process that is processing changes. This is the most important aspect of the interpretation of runs of work as transactions; the intermittent state can be concealed from conforming parties. (It is the "conforming" that makes us call this "optimistic transactions".)
-
Durability refers to the fact that once stored, the state will persist across such things as reboots and power outages. This is a fair assumption to make from LDAP when it responds positively to an update.
See also: http://www.openldap.org/conf/odd-wien-2003/kurt.pdf See also: RFC 5805 which does not seem to be implemented in OpenLDAP or 389 DS?
Design for Monitoring
Note: These monitoring specifications may be too specific where it refers to files; similar results with a much simpler result may be achievable when the data is actually present in LDAP. The important thing is that it can be combined into monitoring information.
The Shaft produces information that is intended to supply monitoring scripts with useful information. In a monitoring directory, it will dump the following information:
- A file for each subtree that it outputs, named after that subtree;
- In each file, the queue of upstream origins, the first one being the active selection;
- For each of these upstream origins, a number in textual representation and an LDAP URI, separated by a space:
- the number indicates the number of levels stripped from the outcome, after which the subtree of the file is inserted;
- the LDAP URI represents the query made with the upstream source.
These files change immediately after the replication process is restructured, so it is even possible to listen for changes in the directory and immediately respond to them. For instance, if a new source is added to one subtree and a preferential treatment of that source is configured by the Shaft administrator, then a script may trigger a manual override to follow the preferred source instead of the current one.
A second monitoring resource indicates which of the upstream sources are offline, again in a directory and using file names that match the subtree it represents. The only concern here is with the top entries of the queues; the second and later entries are not used and downtime of a server is not a reason to start using their potentially different data scheme. An upstream source is only considered offline if none of the hosts that can service LDAP are reachable. If this is the case, the said file is created; it holds one line with number in textual representation and an LDAP URI , separated by a space: - the number indicates the moment at which the downtime was first noticed, as the number of seconds since the Epoch; - the LDAP URI represents the query that fails against the upstream source, and matches the first LDAP URI in the queue description.
In case of downtime of the first element in a queue, Shaft keeps trying to reconnect to the upstream server using an exponential fallback scheme. This is meant to support automatic resolution of transient problems with networks or servers, and may be incorporated into a monitoring regime to avoid immediate alarm during temporary problems. Downtime is not the same as a retraction of a directory, and should not be treated as such. When downtime continues over prolonged periods, then administrator intervention would be required to remove the disfunct server from the head of the queue.
Events that deal with sources going online or offline, or being exchanged, are naturally also sent to the system's logging facility to aid historic analysis.
Finally, the activity of the various clients will be monitored; when a client unbinds (or is unbound), it cannot stay up to date until it binds again and issues a search operation (presumably with SyncRepl). A list of clients that have been configured but that are not online is available for monitoring purposes. (One way of achieving this, if the local LDAP repository is OpenLDAP, is through the accesslog or autitlog overlays.)
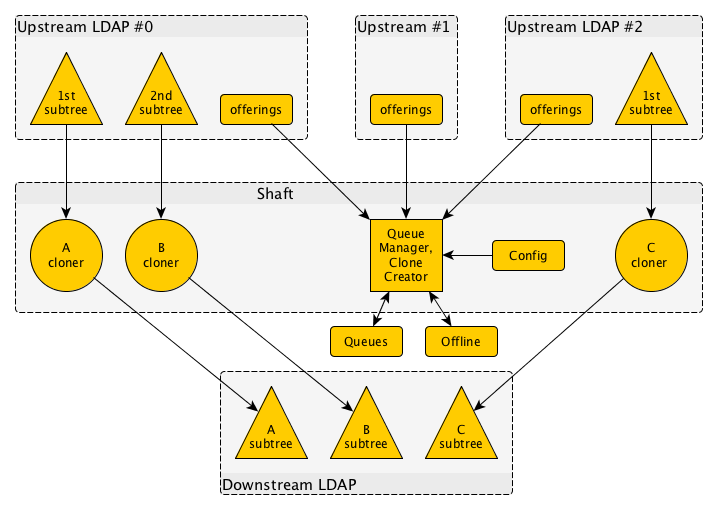
Shaft Operation
The structure of Shaft makes a back-to-back combination of a number of client roles:
- The local LDAP repository is updated by Shaft in the capacity of a directory manager. There should be no human that can override the directory contents in the same capacity, since that might distort the updating process as a result of manually inflicted inconsistencies;
- If the operator sets up automatic expansion of the subtrees provided by some or all of the upstream LDAP servers, then those will be addressed in a refreshAndPersist-style SyncRepl query. This query returns DNs and possibly a few attributes that can be molded into a name for a subtree to setup;
- For each of the subtrees monitored from a given upstream source, the Shaft subscribes through SyncRepl with a refreshAndPersist style query, to download change runs and to incorporate those into the local LDAP repository. (Alternatively, the local LDAP repository might follow the source, but care must be taken not to remove a tree when a replacement origin exists.)
Both Shaft and end user programs can modify the contents of the configuration. End user programs signal to Shaft that it should resynchronise its knowledge against the configuration input. Such resycnhronisation is also performed when starting Shaft.
During a resync, Shaft will compare the configured sources against those that are currently stored in the local LDAP repositories. In case of differences, Shaft will overhaul any subtrees that need to change, following the aforementioned design principles.
Renaming DNs
Shaft can subscribe to lists of DNs, using an LDAP URI. This could for example be used to query for one level below a given baseDN, and filtering on certain conditions. A DN-valued field will reveal the offerings that can then inidividually be added. This is an automated alternative for what can also be done manually: configure individual DNs that can be subscribed to.
For each source, the incoming suffix can be removed and changed into another. For the subscription lists, this means that a rewriting format is necessary. This need not be as generic as regular expressions; it would already suffice to do something along the lines of
turn cn=name,o=org,c=cc into subdom=name, ou="Shaft",o="MyOrg"
Please provide a "virtual attribute" DCList to match sequences of dc=,
to be used like this:
turn cn="Users and Machines",ou="Crank",DClist dom into DClist dom,cn=Upstream, ou="Shaft",o="MyOrg"
...or any other description form.
Access Control for Downstream Shafts and Pulleys
The users of the local repository of the Shaft need to be granted access, and support for this access control is part of the Shaft work package.
Access control relies on an authentication mechanism; Shaft will authenticate with Kerberos. Services using Kerberos are as straightforward to setup as pre-shared keys; we can provision a KDC and service tickets for this project.
The various subtrees from upstream LDAP servers are not considered separately served components in the downstream direction; the Shaft idea is to create one uniform namespace that integrates data that may be composed from multiple sources. So access control basically applies to the entire directory structure offered to all downstream LDAP clients (which normally are Shaft and Pulley clients).
Access control comes down to user identity and credential management; the various Pulley and Shaft components are each identified separately and so they can each be setup with different credentials. This simplifies the retraction of an individual component if, for example, its security is ever compromised. Having one cracked Machine will not carry over to other Machines.
Throughout the Shaft design, there is only one party with write access, namely the directory manager that is operated by Shaft. There is no other party that can write to the local LDAP repository, so all downstream access is read-only. It is perfectly possible to make only a single change at a time with Shaft, so the integrity of the LDAP repository is relatively simple to control.
The objects and attributes shown to LDAP clients may be constrained, so the downstream clients only see those parts that concern them. Limitations of this kind are helpful to protect privacy and, possibly, security of a SteamWorks setup. To this end, it is possible to remove certain attributeTypes or objectClasses from what is being shared with individual clients.
The reasoning that such limitations can also reduce downward traffic is hardly realistic; at least the downstream Pulley instances should request only those attributes that impact their performance, and the SyncRepl mechanism is assumed to meet this desire to only see certain bits and pieces of the directory and its schema.
The access control mechanism is likely to operate on the local LDAP repository, rather than on Shaft itself. It is also likely to be specific to a particular choice of LDAP server -- so be it. The only goal is that the implementation ought to be pluggable, so it can be easily replaced when another directory is used instead of the one for which Shaft is originally created. Compile-time configurability suffices; a separately built module (such as a shared library) is much appreciated.
Program Requirements
Shaft will be a daemon program written in C, using an asynchronous style -- so no threads or process forking other than to fork off to become a daemon. The code shall be suitable for compilation on Linux and Windows, although we may be able to help out with the latter if the code is kept suitably general.
Utility programs for administration are written as a set of functions in a Python module, that may double as a commandline utility for the shell when it is invoked as a main program.
All software interaces will be documented in common formats; man pages for commands and daemons; annotated text formats such as Markdown for APIs, including JSON data formats.
Among the utilities is a FastCGI server that can communicate JSON objects to manually modify the queues, preferred order and so on. The commandline utility can start and stop this server when provided with an IP/port combination.
An independent FastCGI server can communicate JSON objects to modify access control in the downstream LDAP server that is filled by Shaft. The commandline utility can start and stop this server when provided with an IP/port combination.
The reason for providing separate servers for queue configuration and access control is to simplify the distinction between access privileges of wrapping web servers. This means that the responsibility of access control to the configuration of Shaft can be delegated to the wrapping web server.
The software will be delivered in open source, for instance as pull requests to a github repository to be determined. The following license will be applied to the code:
Copyright (c) 2014 InternetWide.org and the ARPA2.net project
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions
are met:
1. Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in
the documentation and/or other materials provided with the
distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.