
SteamWorks' Pulley -- Script Intuition
This document explains the intuition behind Pulley script language. Although the formal mathematical description defines the overriding truth, this intuitive presentation ought to be more appealing to users who seek to make Pulley do something for them.
This site reflects work in progress.
Contents
See also: Formal specification of the Pulley script language.
Generators, Conditions and Output
A Pulley script is very similar to list comprehension, with a few changes:
- its output should be considered a set, just as is customary in mathematics;
- it is written with the components on separate lines;
- the output is the last line instead of the first;
- multiple set comprehensions can be mixed.
Some lines will bind variables that other lines (later ones in the current version of Pulley) can refer to.
A generator is the type of line that binds (zero or more) variables based on LDAP queries that are setup in a global configuration file (not in the Pulley script itself) and it may also refer to other variables.
The syntax of a generator consists of a <- operator, whose left hand side is used to bind variables, while the right hand side pulls from a source of entries, possibly skipping parts of the tree structure. Constants as well as attribute types may be used to match the entries found, and thereby constrain the generated values. Variable names on the right side of <- refer to bindings in other places of the script, and instruct the generator to match the value at the position in which it occurs; variables on the left side of <- are bound by this generator.
Another line that may occur is a condition on free variables. Currently the expressions are limited to LDAP comparison operations. When comparing variables on both sides, the sides must have the same attribute syntax and specify the same matching rule for what the condition wants to do. Note that substring matches are only defined when the wildcards are interspersed with literal data.
The last type of line is the output statement; it defines which of the variables is forwarded to a plugin, currently defined in Python, which drives some form of output to World that runs outside of LDAP and Pulley.
A commented example of a Pulley script follows:
# # Construct alias lists for people on vacation; redirect those to # a secretary backup address, if they have one. # # # The name world is predefined in the global configuration, and refers # to the base DN from which we will generate variables. We do this by # matching parts of the LDAP tree underneath world. # # # Let x be the names of our secretaries in our company. # # The name is stored as a CN under the OU for Secretaries. # The generator binds it to the variable x occurring to # the right of its <- arrow. Literal text, attribute types # and variables on the right side of the <- arrow form a # pattern to match against what lives under world. Mismatches # are silently ignored. # # In terms of LDAP mechanics, a generator is a subscription to # updates that will be passed to this line, and for which # variables will be bound; the new values are called "forks" of # the variable and go out into the remainder of the script to # see if they can make it all the way to output statements. # Mail=x, OU="Secretaries", O="Example Corp" <- world # # We are going to generate a variable "person" that we will ignore in # the further examples below this script. It is however useful to see # how variables may be referenced by the generator following this one. # # Note that this is not necessarily the simplest way of doing this, it # merely serves as an example. # CN=person, OU="People", O="Example Corp" <- world # # Let z be the various people under our company's CN=People subtree. # Let y be the alternative contacts for z. # # Refer to the person variable bound by the generator preceding # this one. The variable is treated as a referral because it occurs # on the right side of the <- and it therefore helps to build a # pattern against which any generated DNs must match. # # This generator contains @z to bind the z variable to the DN at # that point in the tree. This does not match an RDN like the other # components in the generator. Such DN-valued variables can be used # in a similar way as world is done in this example, so as the # base DN in a generator line. # # Note that z,y are bound in pairs, not as independent variables. # Also note that y has a colon, thus binding an attribute instead # of an RDN portion of the DN. Multiple attributes can be bound # with the + notation that is also used for RDNs. # Mail:y, CN="Backups", @z, CN=person, OU="People", O="Example Corp" <- world # # A constraint on z, requiring that the person has a flag set to # indicate being on vacation. # # The schema used is http://www.phamm.org/docs/phamm-vacation.schema # # This demonstrates how the previously bound DN variable for z can # be used in a generator to generate data. In this case, there is # no data retrieved, but rather a pattern matched. This makes the # use of this constraint effectively a condition. # VacationActive: "True" <- z # # Backup persons may be either collegues or secretaries. In order to # look only at the backups that are secretaries, make a cross-reference # between x and y, simply equating them. # # This expresses the desire to find forks for x and for y that have a # matching variable. In LDAP filters, this would compare variables x # to string y, but Pulley scripts can also compare generated variables. # To compare against literal text y, you would have written "y". # # Where generators "fork" multiple values for variables, conditions weed # out those forks that are unwanted. This leads to less output combinations # being produced. # (x = y) # # Output "z" contains all people in our company who have # backup contacts arranged. # # Outputs are plugins that are (currently only) written in Python. The # plugin may have arguments, such as the filename shown below. The # variables listed before -> indicates the variables that are sent over # to the plugin. # # The sort of thing that outputs receive is additions and removals of # the variable combinations that they are setup for. It is up to the # plugin to decide how to handle an addition, or a deletion. # z -> dn_flagset (filename="/var/mycorp/people_on_holiday") # # Output "x,y" is a bit silly, as these values are the same. # x,y -> dbm_map (name="secretary_twice") # # Output "x,y,z" contains all people in our company who have # secretaries as backups, including the secretary. Since x and y # are equal, this same information is supplied twice. Clearly # this provides an optimisation potential, because one variable # can be derived completely from a set of others avaliable in the # set passed to the output plugin. # z,x,y -> dn_map (name="alias_for_dn")
Generator syntax:
The <- arrow matches a comma in a DN; the @varnm can be used to bind a variable varnm to the DN at that point in the chain; the symbol world is not predefined, but by convention this name is bound to the LDAP source in the global configuration; world and variables bound by @ can be used anywhere on the right side of <- to match the sequence of RDNs that it represents; they may also be used to match attributes with a DN-syntax.
The : operator matches an atteribute type/value, whereas = is used for RDNs. It is possible to match multiple attributes, separated as always with +.
Condition syntax:
Conditions are similar to the LDAP syntax, except that it is possible to use variables on both sides; the result is that literal text must always be written as string constants, so literal text enclosed in double quotes.
Output syntax:
Output statements list variables and an arrow -> pointing to the name of a plugin. The global configuration defines how this name resolves to plugin code (as well as which language it is created in -- only Python is currently supported).
Virtual RDNs:
A few special RDN notations are built into Pulley as virtual attribute types; they can be used in generators for special bindings or matches:
- DCList=dnsname binds sequences of one or more dc= RDNs, and combines the components found into a DNS name in variable dnsname;
- SkipOneLevel=rdn binds one RDN regardless of its attribute class(es) and stores the matched result into variable rdn, which is in fact the same type of DN-variable as bound by @z;
- SkipSubtree=rdns binds sequences of zero or more RDNs, and is otherwise similar to SkipOneLevel rdns.
Although these descriptions specify binding, so use on the left side of <- in a generator, they are also usable in matches, both in generators and the upcoming conditions.
Explicit guard:
A line may start with a list of variable names followed by =>, which is an explicit guard, or a condition to the existence of that variable.
- A guard prefixed to a generator means that the given variables must exist before the generator runs; consider it like any variable that is referred to on the right side of the <- with the exception that it does not actually need to be mentioned there;
- A guard prefixed to a condition means that the condition will not be applied if one or more of the guard variables does not exist;
- A guard prefixed to an output line details explicitly which variables must exist before the output can be initiated; this extends the dependencies of an output line an existence of variables.
Script semantics may also introduce implicit guards, but these are not a concern to the programmer of a Pulley script. But this is why the guards in a Pulley script are known as explicit guards.
Generators produce unique records
As shown in the image below, a generator bind a set of variables to values retrieved from LDAP, namely all variables mentioned on the left side of the <- arrow.
LDAP does not generate multiple entries with the same DN; it does not generate multiple attributes with the same value under an entry; and we do not discard information but always bind retrieved information to a variable. The result is that the variables combined with the DN to the right of the <- form a unique combination.
Note that this property is not changed by constants that are mentioned instead of a variable. Such positions merely select which results are generated, but these positions too will have that specified information and are therefore part of the unique pattern.
As an alternative to making the DN to the right of the <- arrow part of the unique set, it is also possible to use the free variables referenced by the arrow's right side. Note that this must include the variable that occurs at the end of the right side.

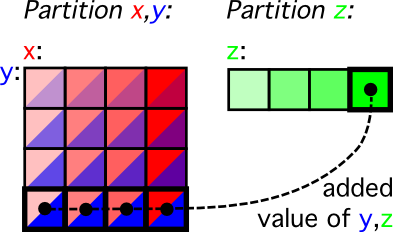
Conditions bring Variables together in Partitions
Rather than looking at generators, the variables are sorted in another fashion while processing LDAP updates in Pulley, as shown in the image below.
In the example shown, a condition refers to both x and y variables, which means that a record consisting of these two variables (depicted as a two-colour square in the image) must be considered. Each of these combinations may or may not be part of the output of Pulley, depending on the condition.
There may be multiple conditions; some may refer to both x and y, others may refer to one of them. But z is in a partition of its own because there are no conditions that refer to both x and z, and likewise there are no conditions that refer to both y and z.

The possibility to connect variables, even across generators, may be the most innovative part of Pulley, because it actually extends the expressiveness of LDAP. In LDAP, conditions always reside within an object; this construct permits you to create conditions that span across objects. But if you don't use this facility the normal behaviour of Pulley is still to keep objects isolated, as shown by the z partition.
This behaviour is in fact similar to the ability of SQL to query multiple tables and then to restrict the outcome by comparing columns across the various tables. It should therefore not be a surprise that records with all possible combinations of x and y variables are shown, just as in SQL where all possible combinations of records from two tables are constructed. As in SQL, conditions help to actually reduce the potentially very large set of combinations.
Please note that the combinations of values in the partitions are not necessily unique; this is because y and z form unique pairs. As a result, the partition for z needs additional y values as they are generated alongside each z to be unique, and likewise every <x,y> record needs the addition of z as generated alongside y to make it unique. This is not a concern while processing conditions (and in fact it may help to avoid repeating the same condition evaluation) but we will need to address this problem when we generate output.
The example given here combines x and y into a partition. There can also be partitions with more than two variables; they will be harder to draw, but Pulley scripts will happily process them. In fact, the partition for z is part of this same general idea; it too stores records, but these just happen to contain a single variable. We could write <z> to emphesise this point.
Forking Variables
In the specification of Pulley, we speak of forking a variable. This means that a variables represents more than one value at the same time. Since the Pulley specification is a declarative language, it does not specify an order of calculation as is in most programming languages; if that were the case we would have had to concern ourselves with the order in which things are done, and we might have used the term iteration. Conceptually, the difference is that the term forking provides no information about relationships with other forks, nor about time ordering of the way the various values are processed.
In the image below, we demonstrate how forking is done when a generator produces a new variable set. In this case, a new pair <y,z> is generated in response to an LDAP update. The new values introduce new combinations in the partitions.
The addition of the new value of <z> to its partition is rather straightforward; it is drawn on the right side of the image below. The process just creates a new value to what the partition represents, and although any conditions on z may still limit if it is passed on to an output, it is an easy to imagine process.
The addition of the newly generated y value to the partition for <x,y> is more complex; it has the potential to combine with any of the already generated values for x. Whether this combination actually exists is subject to the conditions that refer to x and/or y. But as was the case with z, each box for which all those conditions hold leads to an output.
This is where forking is rather visible; the addition of a single value of y can lead to multiple records <x,y> being created. It is as if multiple output changes are independently forwarded. Other than this, the term fork is used loosely, it is just a hint to this process.
In any real implementation, the processor will execute a loop to complete y into <x,y>; if there are more variables like x there would even be a need for nested loops. It is due to the theoretic notion of forking that the implementation has maximum freedom in the order and nesting for such loops. This leaves some room for optimisation that may be handled automatically -- although currently the order of looping simply follows the order of generator and condition occurrence in the Pulley scripts, leaving the task of optimisation to the script author.
The image represents a so-called Cartesian product for each of the partitions. Such a product contains all combination records written out, but it is worth noticing that this structure is not actually stored in Pulley, but that it is merely described; what is stored are indexed values of the dimensions, like x in this example, that are needed to iterate over. Where the Cartesian product represents an enormous data structure, the individual generators basically reproduce the variables that are downloaded from LDAP and considered of interest.
Instead of storing this information from LDAP, it is also possible to download it using LDAP when the need arises. The choice between these alternatives is the subject of a trade-off between network traffic and disk storage, so it is a matter of taste and will be an script author's choice to make. (TODO: It is not yet known if downloading is actually an option; LDAP contents may have moved on, so race conditions might ensue that lead to output being added but never removed, or vice versa.)
Removing Variable Forks
When a variable set is removed by a generator, then its forks are removed from the imaginary Cartesian products, as shown in the image below for the removal of a value of x. This is in fact the opposite of addition.

To determine what needs to be cleaned up, the same process is followed as when adding a new fork. Whether this eventually reaches the output plugins depends on the same conditions as when the dropped value of x was added; the declarative nature of Pulley scripts ensures that the outcome of the conditions are the same. The one thing that differs from the moment of addition is that the output is not directed to add variable sets, but rather to remove them.
As for the creation of new forks, their cleanup will also be implemented as a (nested) loop based on the data that was previousely obtained over LDAP.
Take note that the addition and removal of forks are not separately specified in Pulley scripts. This is deliberate; it leaves the maximum of room to the implementation to maintain consistency, and it offloads this burden from the user. This is easily achievable because the Pulley specifications are declarative in nature.
Generating Output
Based on generators and conditions, we should now have arrived at sets of variables that are worthy of generation of output. This output can take many forms; to name just one example, it could produce an alias lookup table for a mail server, chat server or telephony server. Since the output can vary even when providing the same kind of information, the output is a plugin, which is currently assumed to be written in Python.
The produced output will often be a mapping, such as the mapping from an incoming address to an internal address in case of an alias lookup table. As far as Pulley is concerned, not even the form of a map is an issue. All that Pulley cares about is delivering a variable set to the plugin.
What Pulley does is maintaining a set of records of variables for the plugin. The only basic operations are adding and removing records, which may make the plugin modify a lookup table, or whatever else it needs to do. In addition, a two-phase transaction protocol is supported by the plugin to activate a set of additions and/or removals. Extended APIs may be supported by plugins, which may yield better efficiency. It is dependent on the output's workings whether these extensions can be provided, so Pulley will be flexible where it must, and exploit extensions where it can.
The image below demonstrates the generation of output from a few records in the partitions. In fact, two record additions are shown here; they are considered to be paired, probably because the new values for y and z come from the same generator phase. It is probably that other combinations may also be produced by the same generator activity, but that is now shown in the image.

One of the outputs produces a single z. This information is provided to the plugin. As explained above however, the value of z is not unique in this example, so simply adding or removing the value is not directly possible; repeated additions might be ignored, but then the first removal would entirely remove the z value from the output, which is not intended because at the time of removal of a variable set with values for y and z there may still be other values of y for which a matching z is available.
To avoid this problem, we should always invoke an output with records that hold, for each of the generators, either all or none of the variables generated. This means that we need to add variables that are missing from the partition's record. In the case of z that means that y must be added.
Since apparently it makes no sense to add y to the output's parameters, it is instead added as something that we call a guard. Parameters plus guard forms a unique combination, and so an add introduces a fresh combination and a remove can utterly strike all memories of a combination.
Similarly, the output for x and y requires z as a guard because it is generated alongside y. Only the output for x, y and z is complete and does not require a guard -- or more precisely put, its guard is empty variable set.
Not all plugins may support guards however; in those cases, Pulley can compensate by wrapping something around the plugin, but it is usually more optimal if the plugin itself can care for guards. In case of an alias map, there may be room for the guard's value in a comment that does not end up in a database generated from a text file; it would suffice if the comment merely counted how often a mapping was added minus how often it was removed.
Optimising Pulley's Flow
Script order:
The main thing you can do to improve Pulley's efficiency is to place lines with guards and conditions in a good order. The general idea is (currently) that the various components that need to be executed at the same moment are run in their order of occurrence in the Pulley script.
This means that the most restrictive things should be done as high up as possible. For example, if two conditions work on x and/or y variables, and one of them is expected to weed out 80% while the other only removes an exceptional 3% of the cases, then the 80%-weeding condition should be put first. It is also a good idea to place conditions on variables before generators that use them for the further production of entries to work on. Logically, these changes have no impact but the runtime efficiency of Pulley may improve dramatically.
Plugin authors:
When writing a plugin, consider the extensions that complicate your code, but that may considerably simplify the operations of Pulley. If you have a position to put a counter for the number of additions minus removals, put it in. If you can iterate over the values stored and could use those to remove combinations, specifically if that can take guards into account, use it.
One of the classes of plugin supported is an output channel for mere hints. These are notifications that a record may have been added, or removed, but that a check is needed in order to check this. This may be useful for all sorts of caching applications, where LDAP is not used as the full truth, but merely as a notification channel.
Plugins need to support the two-phase commit protocol, including the storage of an opaque byte string to identify the commit number. This byte string is used to identify upstream LDAP repository versions in the SyncRepl protocol, and at the same time it serves after a restart of Pulley to determine whether all plugins and caches are on the same page.
When designing your directory, it is worthwhile to attempt to split into subtrees that Pulley can load all at once, usually representing something mechanic like CN=Users. Contrary to a top level in dc=,dc= style, this means that smaller trees can be subscribed to over LDAP SyncRepl, and so less network traffic is needed than when Pulley can only filter out entries at a lower level, after they have been downloaded.
Script Expressiveness
Directory structure.
Conceptually, the LDAP queries are global, and generators pickup entries that match in order to bind variables and fork values for them. It is however still possible that a generator is implemented more optimally through a separate LDAP connection, asking only for a subtree and for attributes that matter for the generator and any further ones depending on them.
In such optimising implementations, it is helpful if the top of the LDAP tree splits first in the kind of data, and only then into the identities that are all going to be handled in generators by binding them to variables. For instance, the following two structures may seem equivalent, but their SyncRepl subscriptions are cut off at different points, making the latter far more efficient:
UserID:uid <- CommonName="Whitelist", DCList=dom, world UserID:uid <- DCList=dom, CommonName="Whitelist", world
Object crossover.
Pulley is much more expressive than LDAP on its own; the ability to query and compare attribute values in different objects is a valuable addition, and it enables things such as group permission evaluation on the client side. This is also possible with a number of sequential queries over LDAP, but this is more difficult when a complete overview is desired, such as is the case with typical Pulley applications.
In fact, LDAP with Pulley in front of it comes a long way to meeting the expressiveness of SQL. This is enabled without distorting LDAP's most powerful asset, namely that it is a standardised query language with standardised-but-extensible collection of objects and attribute types.
Positivism.
One thing that is not currently part of the Pulley specification language is negativity; all things expressed are positive and generate new data. The clearest demonstration of this fact is the meaning of a condition x != y that disables records with the same value of x as for y -- but that does not mean that an x is suppressed if only one of multiple values for y equals it; the condition requires that some value of y differs from x. This is a vital distinction in situations where y can take on more than one value. (The same reasoning can be applied in the opposite direction.)
For now, negativity is not expressed in Pulley's scripts because we have not decided on how to formulate it. We are considering to retain the simplicity of the scripts by creating a mechanism for output plugins to cancel out against each other.
For instance, it is not possible to implement a blacklist in Pulley; the only thing that can be done with a blacklist in LDAP is to pass on its records to a configuration file for a server that implements blacklisting. However, future versions of Pulley might output some records to a whitelist and others to a blacklist output, and make a cancellng connection between these outputs so that the remaining whitelist would end up with all permissible actors but not any that appears on the blacklist. As said, this has not been decided yet, but it appears to keep the scripts themselves elegant, simple and above all, easy to read.